

认识SDXL模型
SDXL模型是由StabilityAI于2023年下半年发发布。
训练集分辨率:1024x1024px
文本编码器:采用OpenCLIP -ViT/G + OpenCLIP -ViT/L;双CLIP组合
支持语言:英语
提示词形式:tag+短语形式/自然语言
生成类型:图像
UNet 参数数量:2.6B
优点:支持较为复杂的语义理解,还支持多种风格
生态:SDXL拥有非常繁荣的生态环境,并衍生了多种微调模型分支,对动漫类图像有非常好的支持,是目前最常用的动漫绘画模型之一。
- base(基础)模型
- refiner(精炼)模型 质感、光影、纹理等方面有更好的效果。
模型下载
网盘下载:https://pan.quark.cn/s/76b1149dd741
存放路径ComfyUI\models\checkpoints,如果非checkpoint模型还需根据实际情况存放。具体参考,传送门:1.02 SD1.5图像生成基础原理、熟悉comfyui工作流界面快速入门,搭建第一个工作流
更多下载渠道⬇⬇⬇
搭建SDXL模型工作流
基础工作流
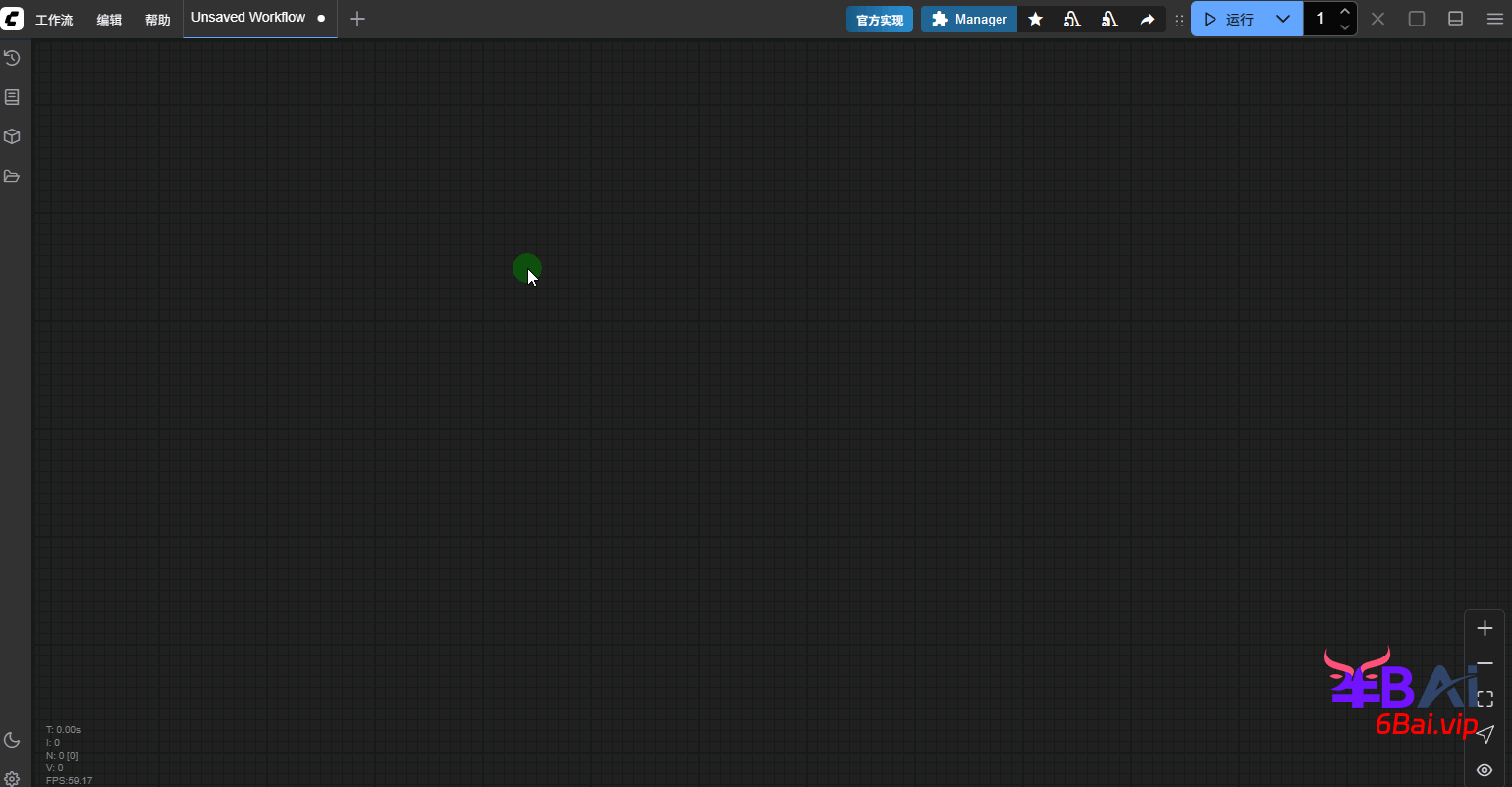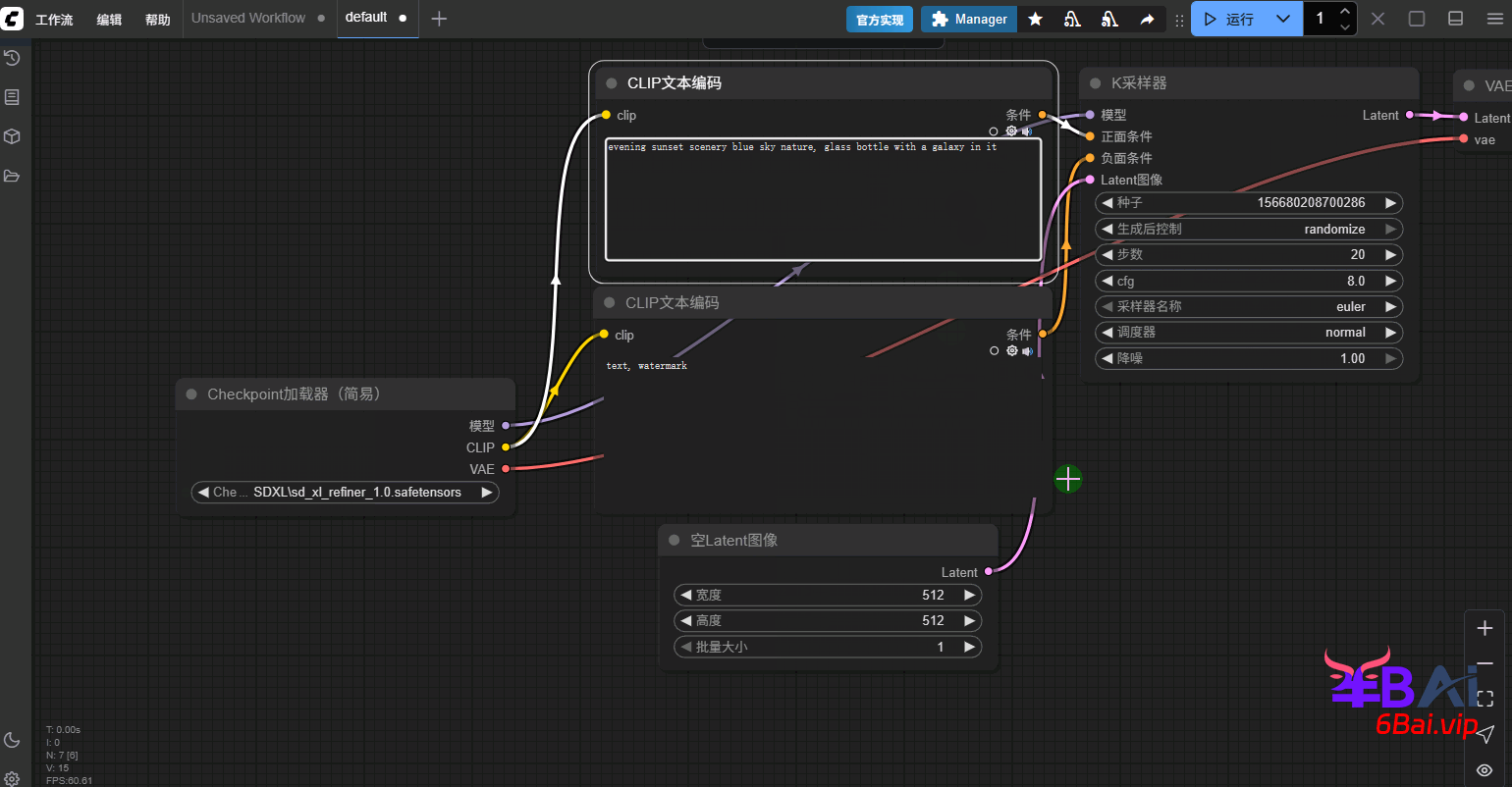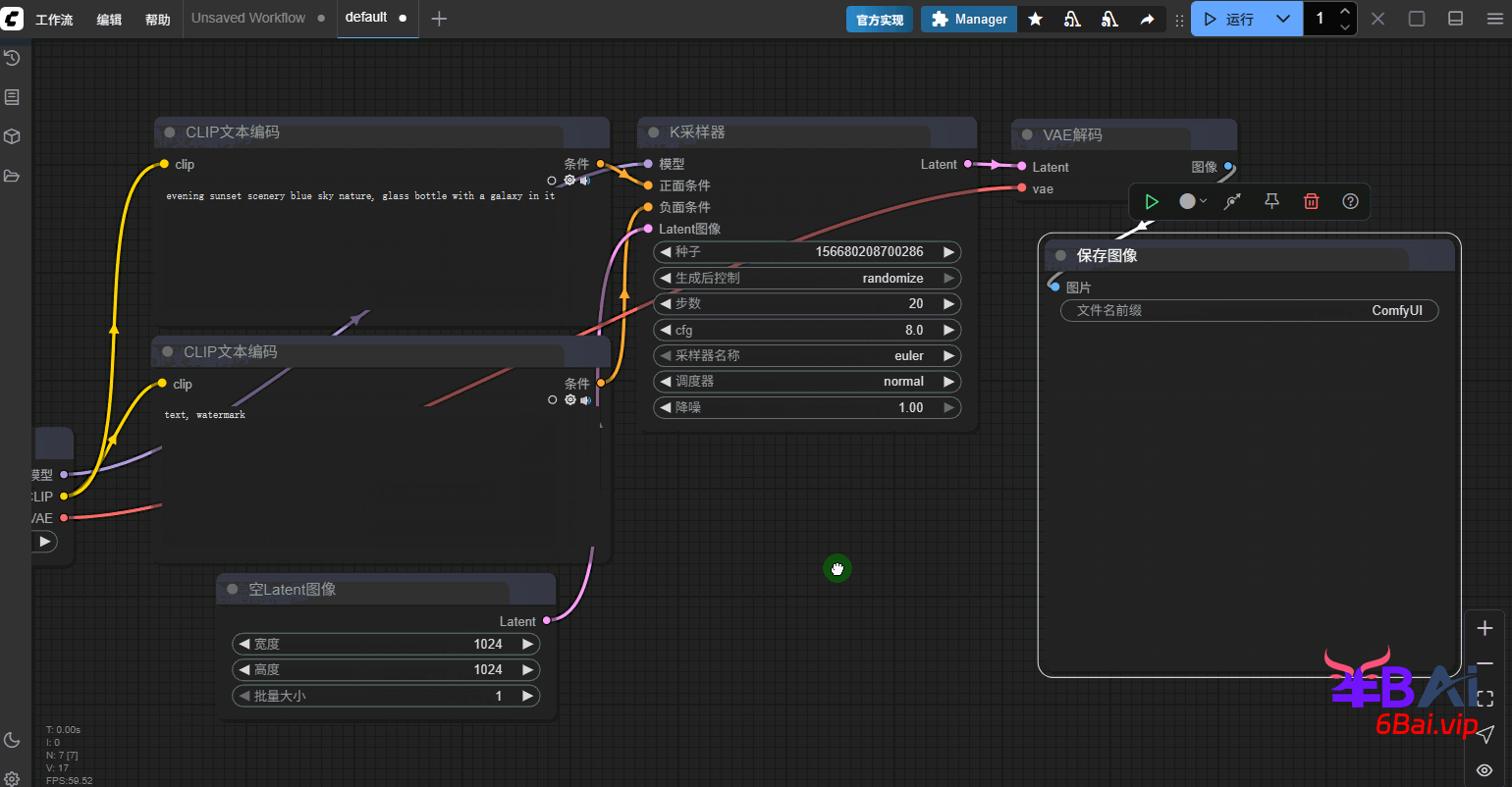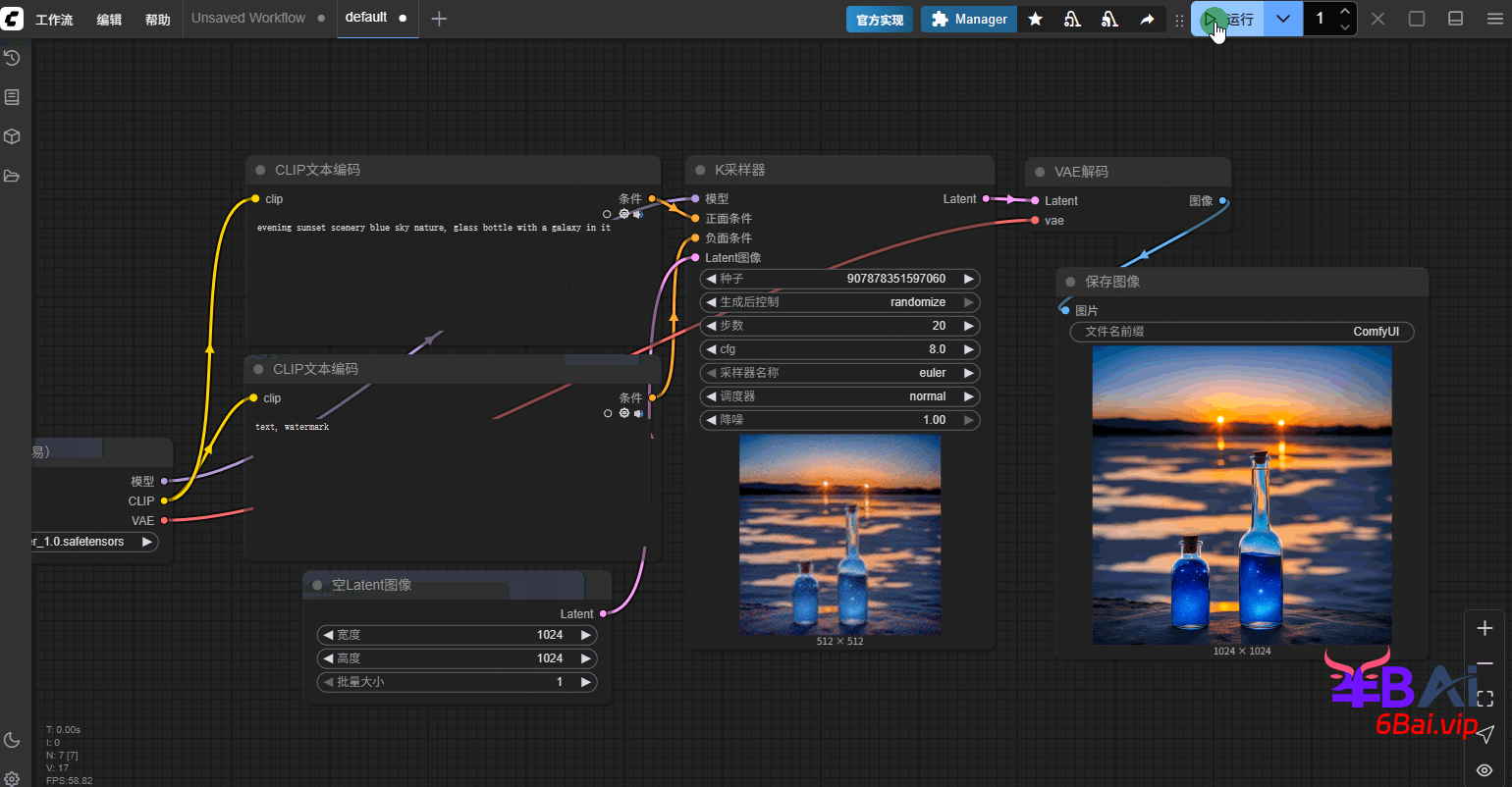
基础的SDXL模型工作流搭建非常简单,仅需使用默认的工作流,将模型切换为SDXL模型,图像尺寸修改为1024即可。
示例提示词:
evening sunset scenery blue sky nature, glass bottle with a galaxy in it如图所示:
多阶采样工作流
除了使用基础模型搭建简单的工作流,还可以配合精炼模型搭建更复杂的工作流,既多阶采样。多阶采样也是在comfyui中经常使用的技术之一,可以通过多阶采样完成对图像进行二次渲染,以达到精修、放大、图像调整等操作。
多阶采样通常有两种方式:
当然使用上述的精炼模型进行二次采样并不常用(因为绝大部分的多微调模型,都无需使用精炼模型),但是这种多模型配合,多次采样出图的思维,为我们以后的创作提供了更多解决方案的可能。
SDXL风格提示词
在一开始就介绍了,SDXL支持多种风格,我们只需要在提示词中输入对应的风格提示词,无需使用微调模型或Lora模型就能完成不同风格的绘画。
对于不同风格的提示词可以参考这个网站:https://rikkar69.github.io/SDXL-artist-study/
可视化的风格提示词节点
除了去手动摘抄提示词,我们还可以借助第三方节点来完成这个工作,只需要在comfyui工作流中简单的点选操作就能实现对应的风格。
节点名称SDXL Prompt Styler,我们可以使用管理器或者git clone来进行安装,还不懂安装的朋友可以参考,传送门:安装常用第三方节点/插件,中文汉化和提示词翻译节点
git安装命令:
git clone https://github.com/twri/sdxl_prompt_styler.gitgithub地址:https://github.com/twri/sdxl_prompt_styler
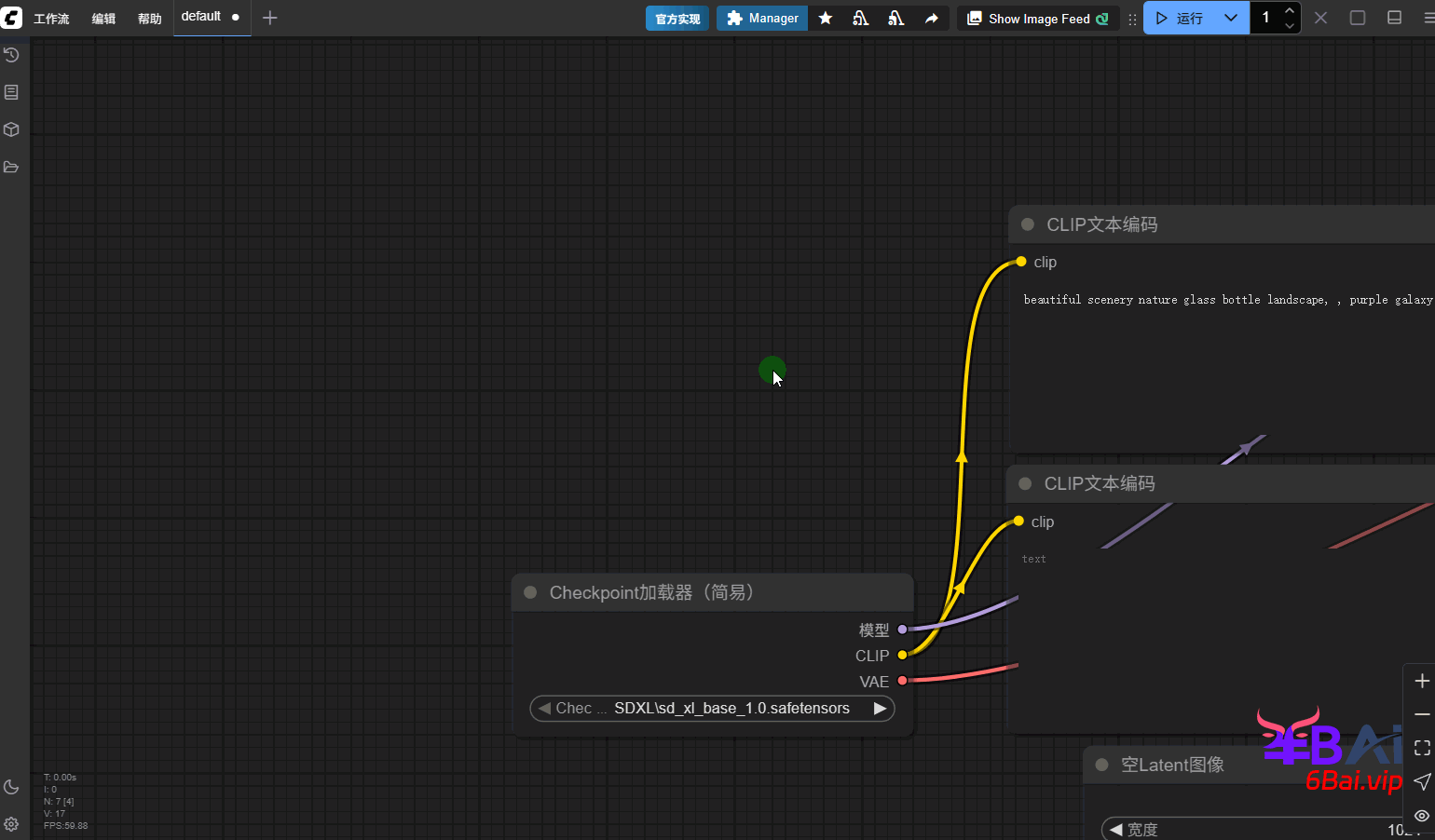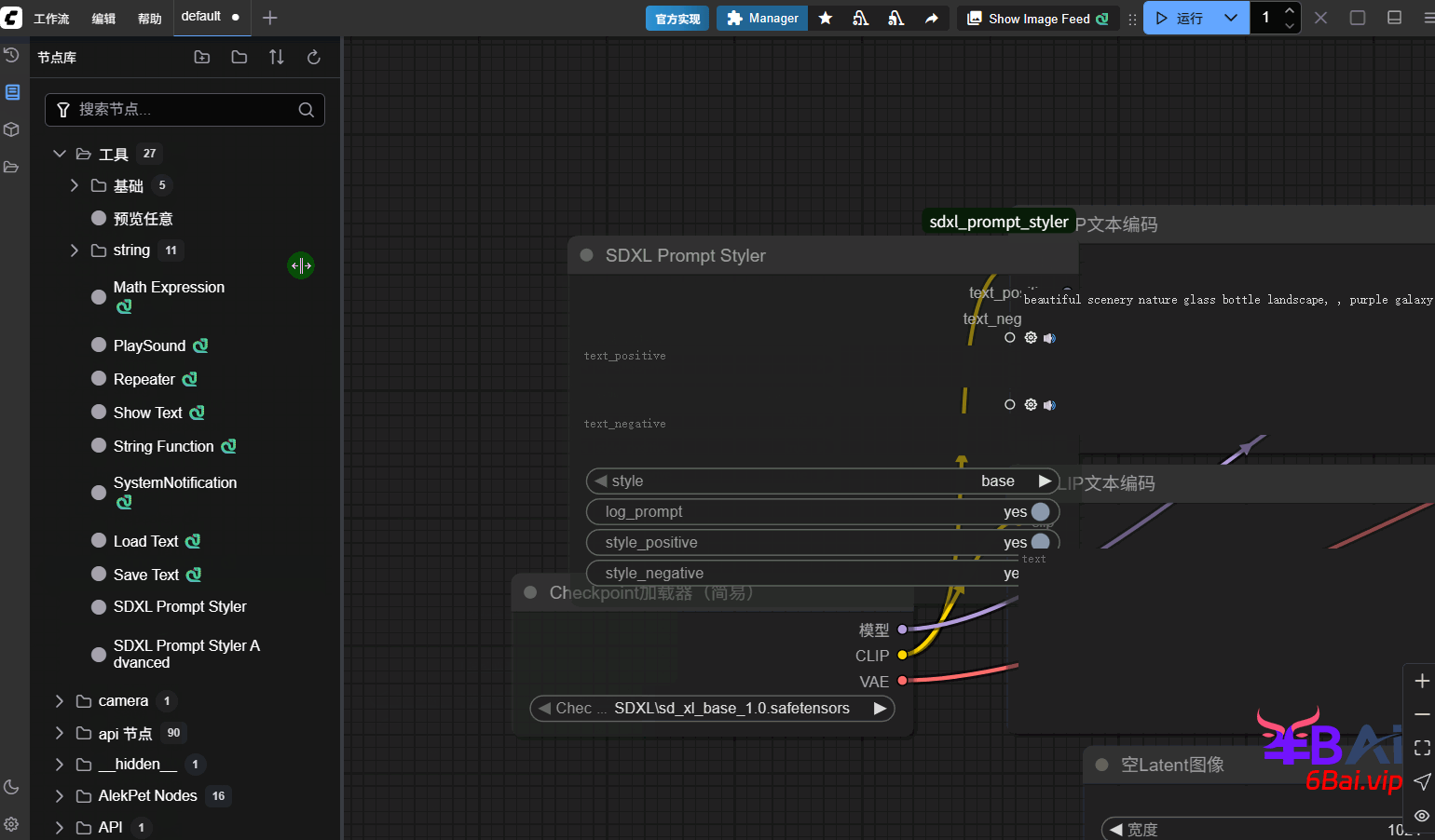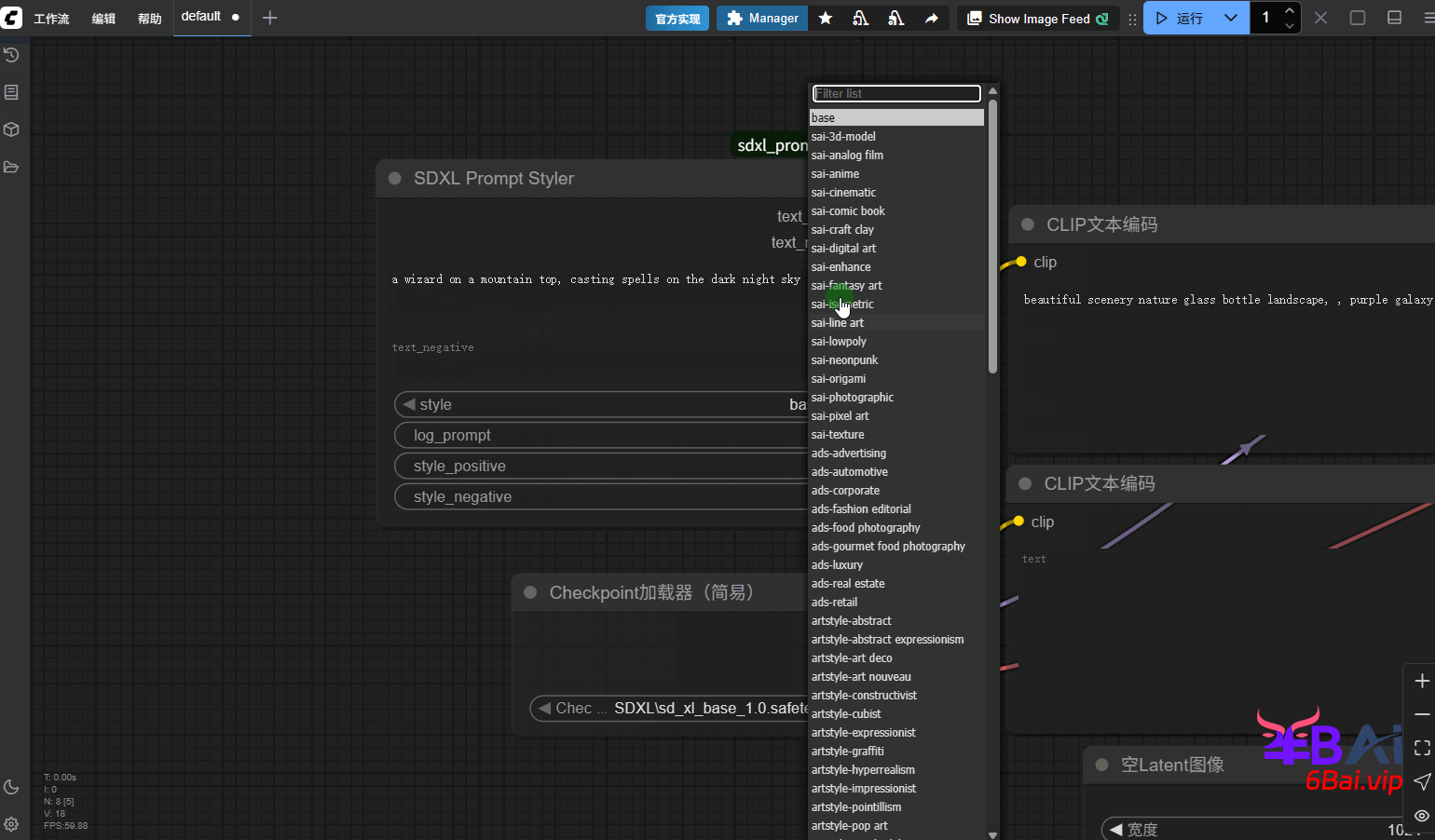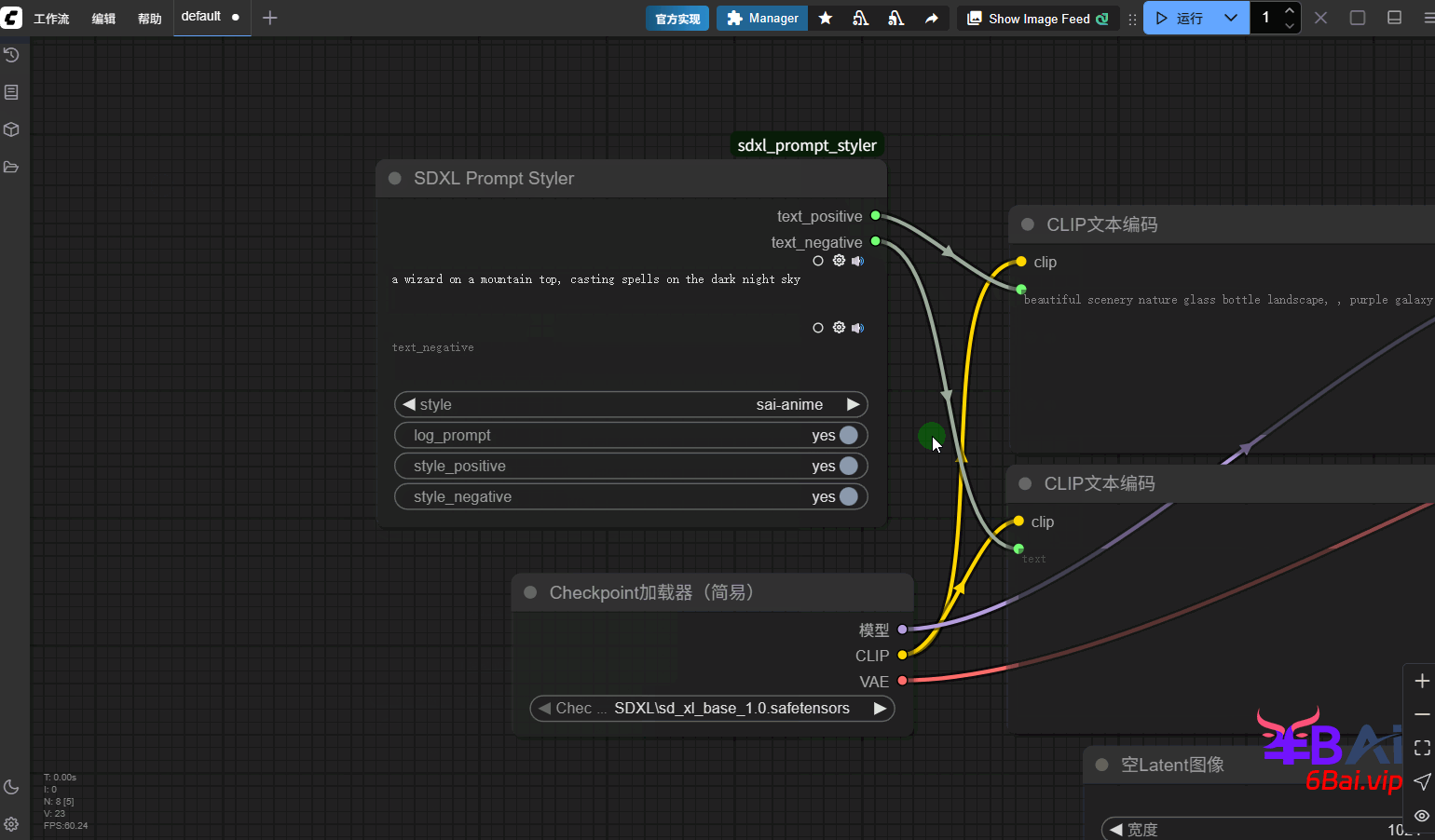
安装完成该节点后,可以尝试简单的使用该节点。在找到节点库→工具→SDXL风格化提示词
英文版:节点库→utils→SDXL Prompt Styler
将该节点拖拽出来,在text_positive中输入正面提示词,text_negative中输入负面提示词。
示例提示词:
a wizard on a mountain top, casting spells on the dark night sky风格(style)选项中选择一个合适的风格,基础(base)表示不使用任何风格。最后在将正面与负面条件的输出连接到clip文本编码器的文本输入,如图所示:
以下是我使用示例该提示词,并固定种子,采用不同风格得到的图像。

除了上述简单的提示词应用之外,该节点还提供了一个额外的高级节点。





评论(3)
这里CLIP文本的右键找不到转换为输入,是目前版本已经更新掉了,还是我个人的操作失误?
已经更新了,把线拉到需要转换为输入的地方,鼠标释放即可自动完成转换
好的谢谢~!