

认识Wan2.2模型
由阿里通义万相于2025年,年中发布的一款开源模型,在wan2.1的基础上升级而来。在一定程度上wan2.2与wan2.1是相通的,这里不在讨论wan2.1,以wan2.2为主。
理解图像与视频的本质
有影视剪辑基础的伙伴,应该非常清楚关于帧率这一概念。或者玩过FPS游戏的玩家,也对帧率这一概念有一些了解。
帧速率fps
一段视频内容,本质是由多张有序的画面(图像)组成,帧速率(fps)是一段视频中的重要参数之一,它规定1秒视频内容中有多少张图像,每张图像表示一帧,在单位时间内图像越多,视觉上最直观的感受就是视频越流畅。帧速率也可以叫做帧频率,用赫兹(Hz)表示。
例如下面有一组由80张,有序组成图像组成的一名马拉松运动员跑步画面,如图所示:
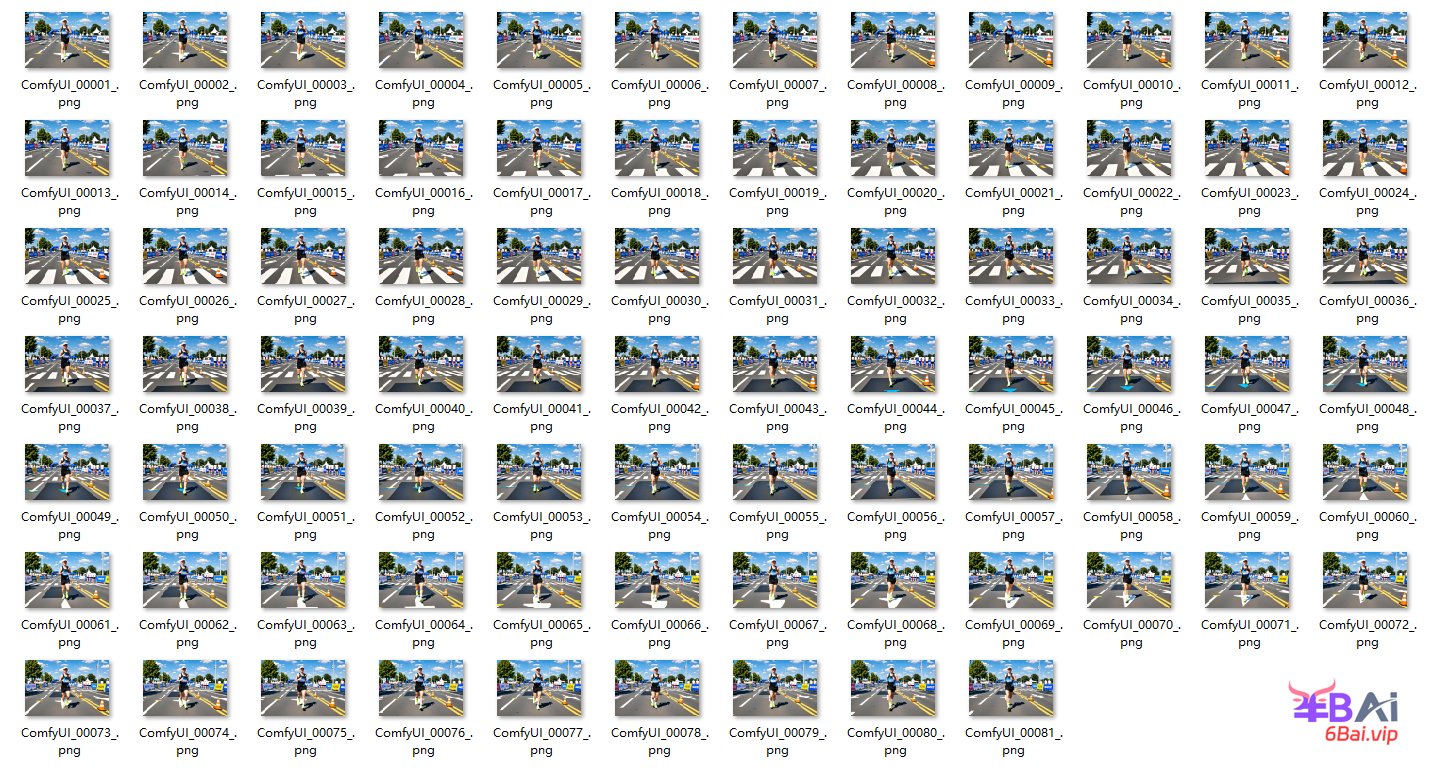
图像下载:https://pan.quark.cn/s/13c8d12f1a8c
硬件要求
wan2.2是一个参数量非常大的视频模型,能力强的同时,对硬件(显卡)要求也显著提升,满血版fp16单个模型容量达到了恐怖的约30GB,这意味着我们可能需要一张RTX 5090 32G显卡或者4090 48G魔改版本显卡才能进行推理。即使是fp8_scaled的量化模型有约16GB容量,意味着可能需要4090 24G显卡才能顺畅运行。虽然低显存也能运行,但建议至少12G显存可以尝试f8模型,并且需要有足够的内存,若内存不足可以开启虚拟内存,但这体验不会很好。
借助云端
👉️👉️👉 推荐云端1(送10元免费体验,需实名认证后到账)
👉️👉️👉 推荐云端2
👉️👉️👉 在线comfyui(送1000积分,每天在领100积分)
工作流搭建
在开始之前,应确保confyui已经升级到版本,当前演示为v0.3.52,至少等于或高于此版本。
文生视频 t2v
模型下载
网盘下载:https://pan.quark.cn/s/3946bdb88b23
- 模型目录结构说明,更多下载渠道⬇⬇⬇
7、对K采样器(高级)节点的参数做一些调整,首先是两个采样器之间的配合,参照之前的K采样器(高级)多阶采样。采样器与调度器依旧可以使用经典的euler/euler a + simple,cfg值通常在3-5之间,使用3.5/4是一个非常不错的推荐值。最后加入合适的提示词,下方是一个提示词案例。
正面提示词:
一位参观者正站在一幅画前欣赏。镜头向右移动,跟随她的脚步,展现出她旁边墙上挂着的一系列风格统一的画作。负面提示词(wan2.2对负面提示词注重并不高,可以将该词作为通用提示词):
色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走,裸露,NSFW完整的工作流,如图所示:
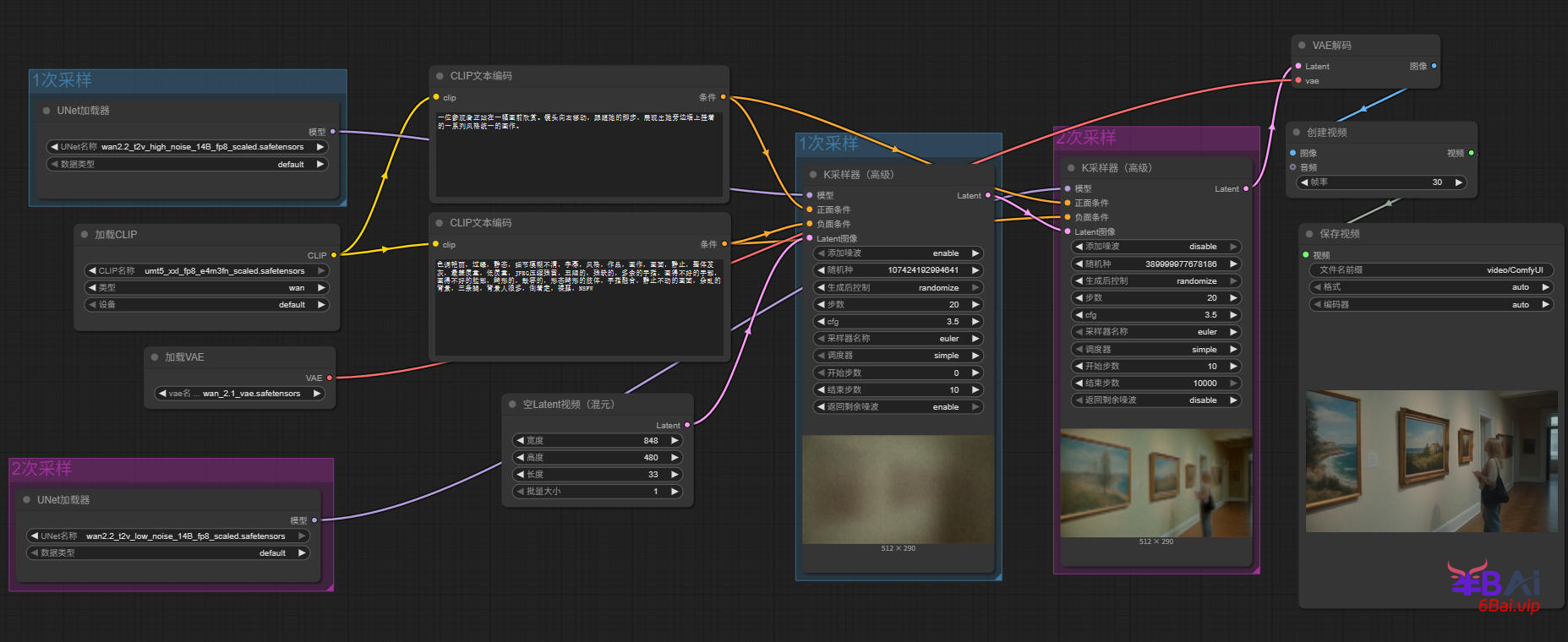
除此之外,同样可以采用之前接触过的K采样器(高级)来完成二阶采样的工作流。传送门:搭建SDXL模型工作流,理解多阶采样与高级K采样器、SDXL熟悉风格提示词
图生视频 i2v
关于i2v同样在comfyui的默认模板中,也为我们提供了一个简单的示例。当然我们也可以在刚刚的t2v工作流的基础上,进行一些简单的修改,就能完成i2v工作流的搭建。
i2v工作流不在需要空latent视频,将该节点删除。需要用到一个新的节点,Wan图像到视频(WanImageToVideo)。该节点位于:节点库→条件→视频模型→Wan图像到视频。
1、将Wan图像到视频节点添加到工作流中,该节点的正负面条件输入,与clip文本编码器的正负面输出连接,正负面输出与K采样器正负面输入相连。latent输出与第一次采样相连。如图所示:
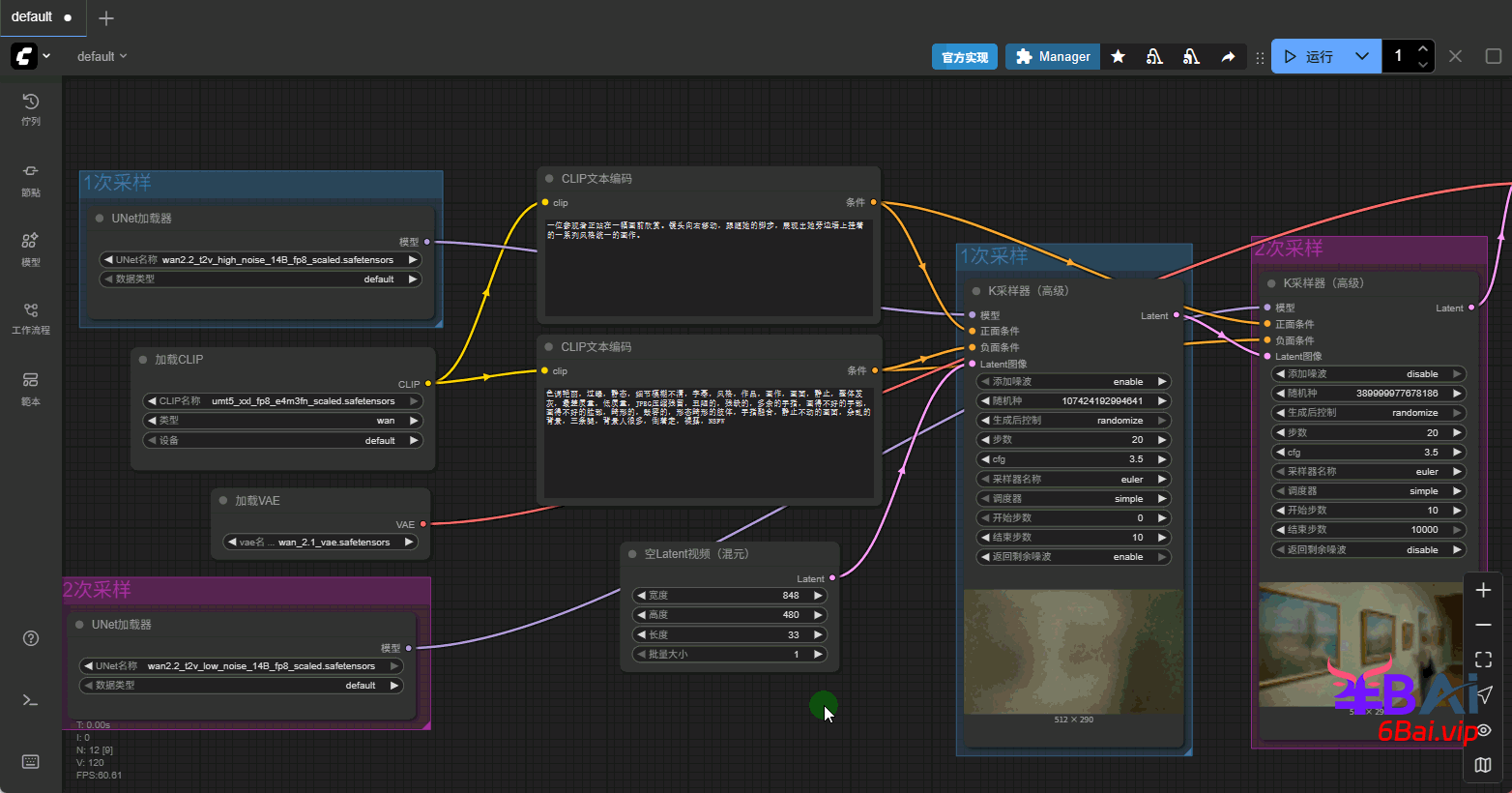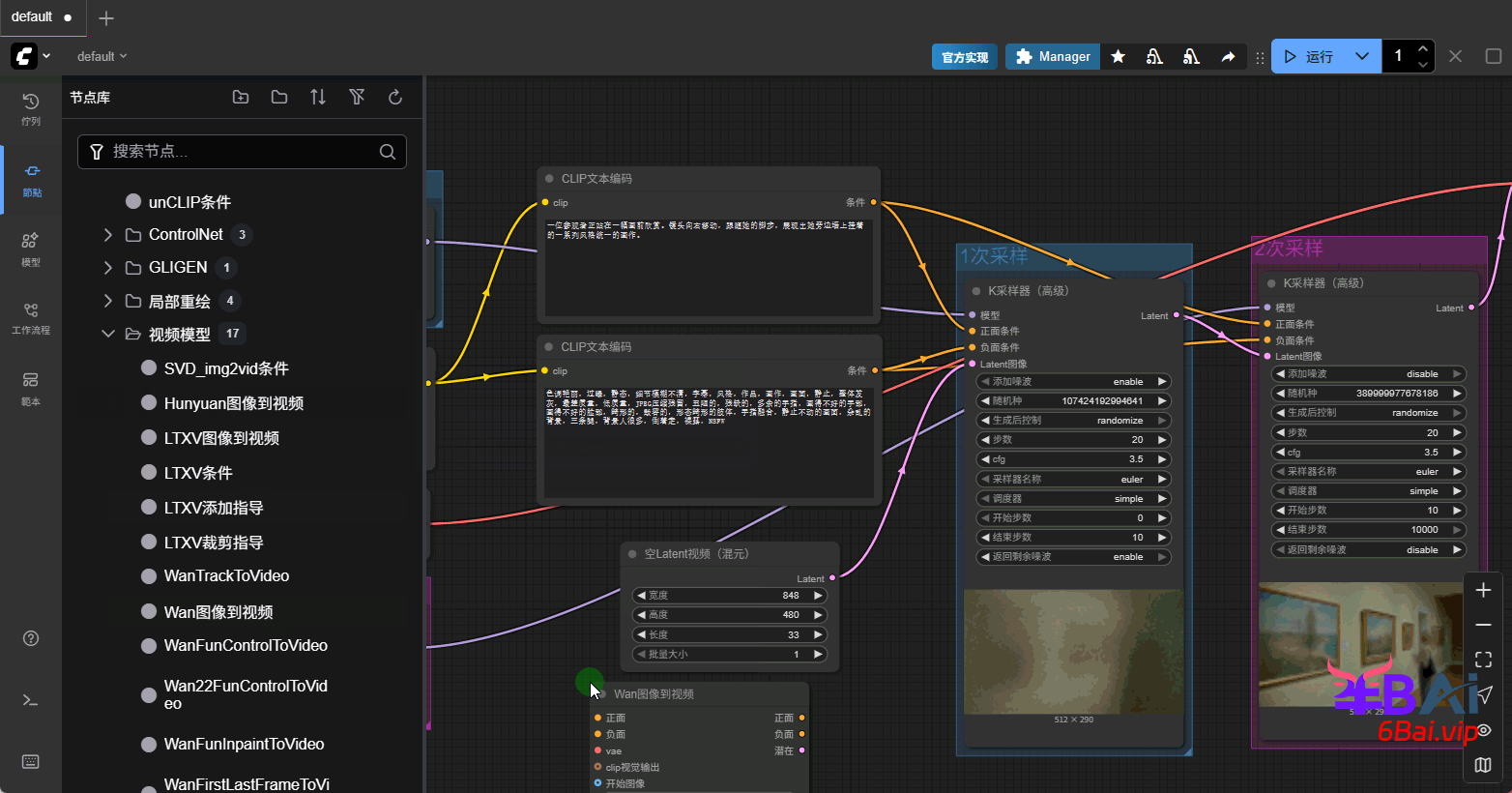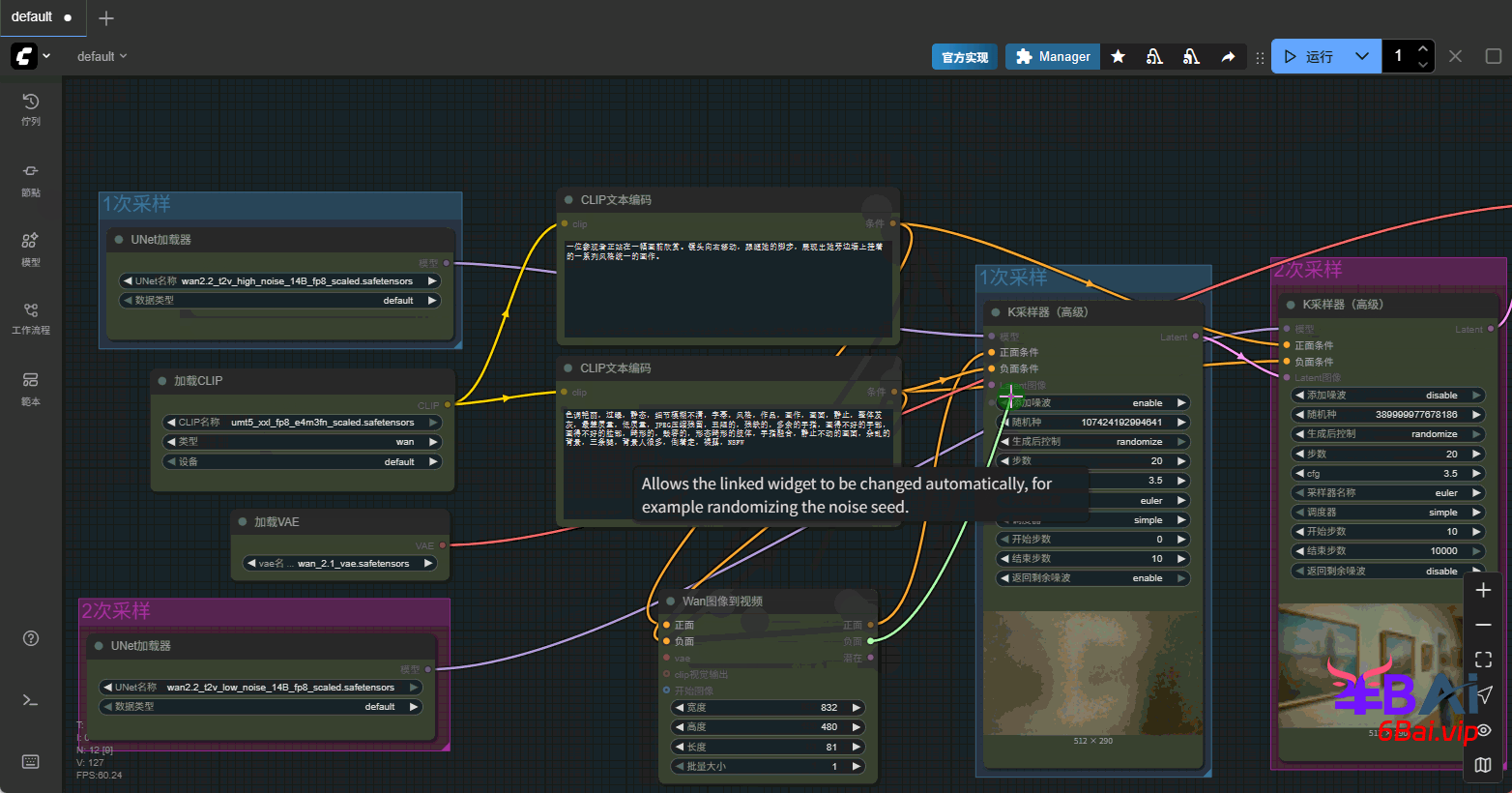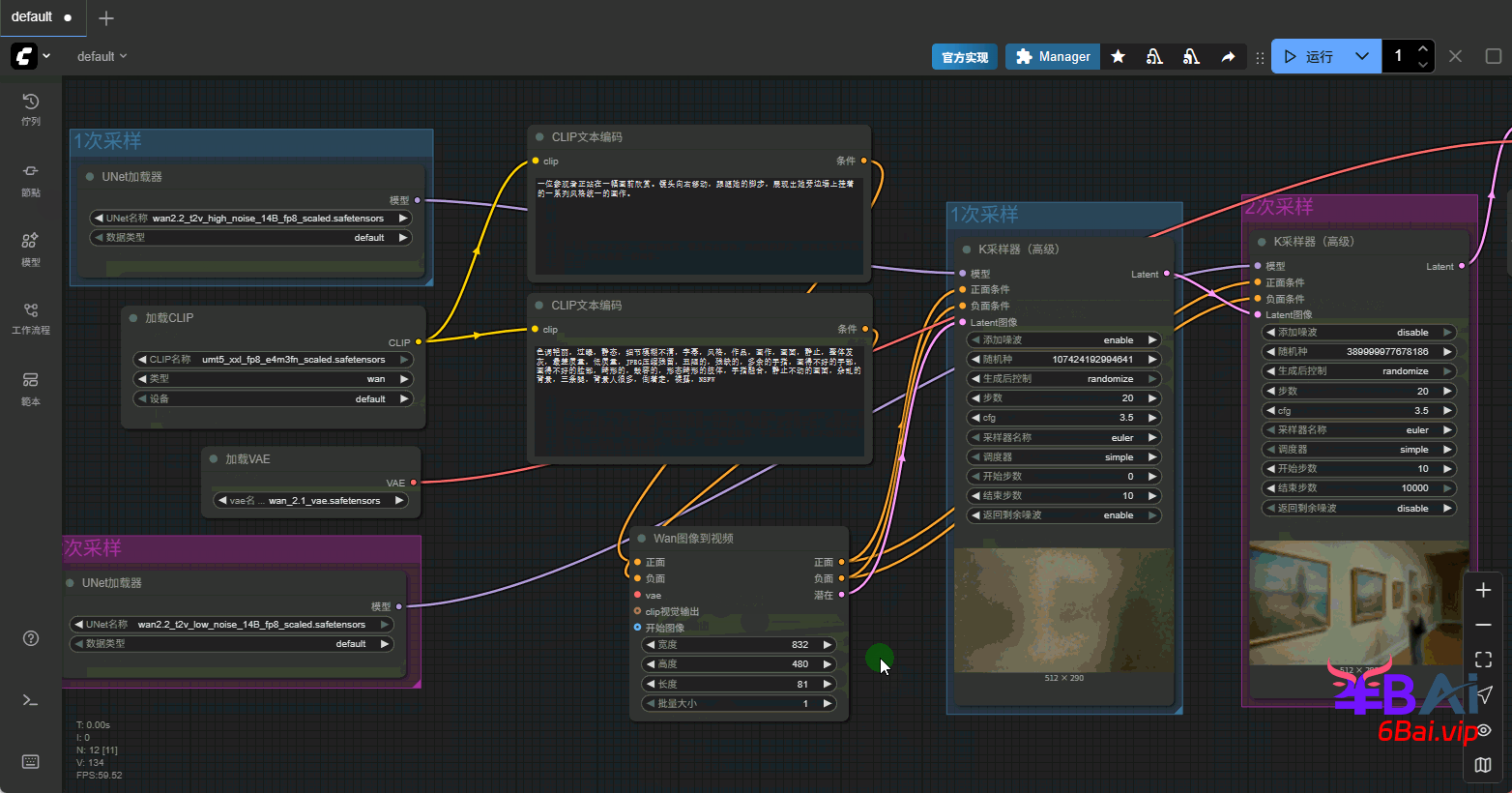
关于clip_vision
clip_vision(clip视觉)模型,是之前没有接触过的内容,它用于将图像特征编码成embedding,简单来说使用clip视觉时,无需对图像进行描述,在提示词中只需要关注动态内容即可。
clip视觉模型
存放路径:ComfyUI\models\clip_vision
网盘下载:https://pan.quark.cn/s/577527755947
更多下载渠道⬇⬇⬇
提示词公式
提示词用来描述视频中所包含的内容和运动过程,它是控制视频画面内容与效果的关键因素。提示词描述越完整、精确和丰富,生成视频的品质越高,且越贴近期望生成的内容。
基础公式
适用于初次尝试AI视频的新用户,及将AI视频作为灵感启发的用户,简单自由的提示词可生成更具有想象力的视频。
- 提示词 = 主体 + 场景 + 运动
进阶公式
适用于有一定AI视频使用经验的用户,在基础公式之上添加更丰富细致的描述可有效提升视频质感、生动性与故事性。
- 提示词 = 主体(主体描述)+ 场景(场景描述)+ 运动(运动描述)+ 美学控制 + 风格化
图生视频公式
图像已经确定了主体、场景与风格,因此提示词主要描述动态过程及运镜需求。
本文工作流
加速优化方案
使用Lightning加速
Lightning是由作者Lightx2v发布,在wan2.2的基础上蒸馏而来的加速模型,可以使用极少的步数,4步完成采样。以lora的形式存在,在comfyui中和使用普通lora模型一样,将模型串在模型加载和k采样器中间即可,如图所示:
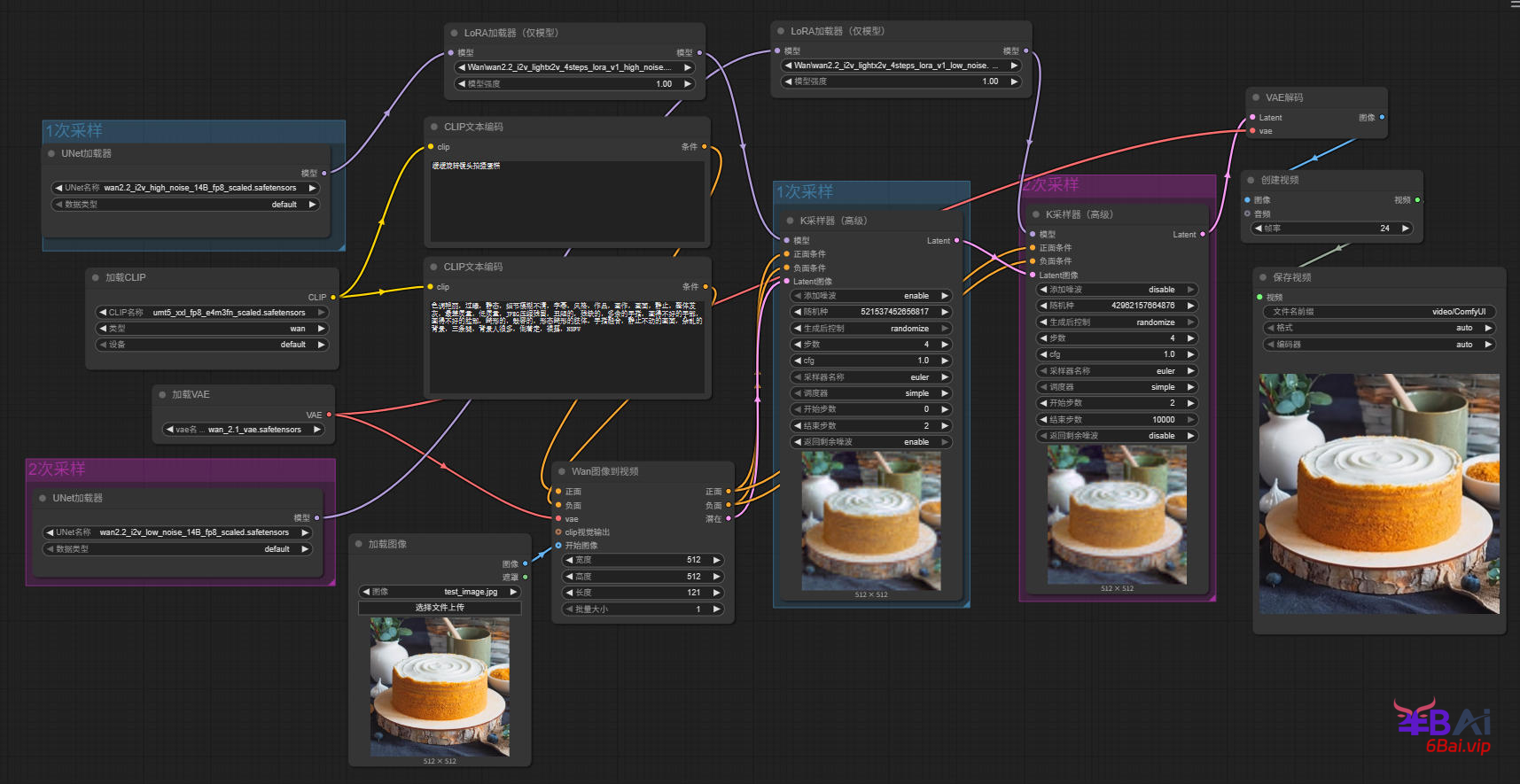
模型下载
在前文中的模型里,已经提供了该lora模型。
使用gguf量化模型
使用gguf量化模型之前,需要额外安装一个第三方节点,传送门:gguf量化模型节点安装使用指南
如果本地有12G或16G显存的显卡,gguf模型可以用gguf加载器,也可以使用kj的wanVideo节点,kj的wanVideo节点后续会专门讲。
gguf模型下载
网盘下载:https://pan.quark.cn/s/0caee5955104
存放路径:ComfyUI\models\unet
更多下载渠道⬇⬇⬇
使用kj节点的工作流
传送门:待完善
使用Nunchaku(双截棍)
传送门:待完善
wan2.2的衍生模型
除了wan2.2 t2v 5B模型与t2v和i2v 14B模型之外,wan2.2还衍生出一系列相关模型。








评论(0)